【Snowflake】SnowflakeにShapfileをロードしてみた
※2023/08/22現在、Issue#1006によりSnowflakeFile関数が利用できなくなっているため、関数を使ったロードができない状態なので注意
概要
GIS(地理情報システム)でよく使われるShapefile形式のデータをSnowflakeへロードする。
なにかいい方法がないかと模索していたら、めちゃくちゃ参考になる記事があったのでこれを元に試してみる。
使うデータは国土数値情報データの行政区域(全国)のデータを用いる。
ロード方法
1. 事前準備
Snowflake上でUDFを作成する際に、Anacondaのライブラリを利用する。
ライブラリを利用するにはSnowflakeサードパーティ規約に同意しなくちゃならない。(参考)
まずはSnowsight上のAdmin >> Billing&Termsの画面にいき、AnacondaのEnableのボタンをクリックする。
すると以下のようなポップアップ画面が出てくるので、「Acknowledge & Continue」をクリックして同意する。

同意が完了すると、画面には「Acknowledge」と表示される。

2. UDTFの作成
他にいい方法が思いつかないので、参考記事に記載のUDTFを少し加工して利用する。
(ほぼコピペだけど。。)
-- DBの作成
CREATE DATABASE SAMPLE_DB;
-- スキーマの作成
CREATE SCHEMA SAMPLE_SCHEMA;
-- UDTFの作成
CREATE OR REPLACE FUNCTION LOAD_SHAPEFILE(path_to_file string, filename string)
RETURNS TABLE (wkb binary, properties object)
LANGUAGE PYTHON
RUNTIME_VERSION = 3.8
PACKAGES = ('fiona', 'shapely', 'snowflake-snowpark-python')
HANDLER = 'LoadShapefile'
as $$
from shapely.geometry import shape
from snowflake.snowpark.files import SnowflakeFile
from fiona.io import zipmemoryfile
class LoadShapefile:
def process(self, path_to_file: str, filename: str): # ファイル名はzipファイルの中のshpファイル名を指定
with snowflakefile.open(path_to_file, 'rb') as f:
with zipmemoryfile(f) as zip:
with zip.open(filename, encoding='shift-jis') as collection: # エンコードはSHIFT-JISを指定
for record in collection:
yield ((shape(record['geometry']).wkb, dict(record['properties'])))
$$;
作成した関数はUDTF(user-defined table function)と呼ばれ、普通のUDFとは少し異なるので注意する。
SnowflakeにおいてUDFには2種類あり、一つはスカラー値をリターンするUDFなるものと、もう一つは表形式の値を返すUDTF(user-defined table function)が存在する。
なお、UDTF作成時に注意すべき点は以下のとおり
- ハンドラー名はクラス名と一致する必要がある
- ハンドラークラスが必須
- processという名前のメソッドが必須
上記が満たされてないとエラーになるみたい。詳細は公式ドキュメントを参照
3.データをロードする
今回用いるデータは50MB以上あるためSnowsight上からではなくS3経由でロードする。
まずはS3バケットにデータを格納する。

Snowflake上で必要なオブジェクトを作成していく。
※S3 Storage Integrationの方法は割愛
USE DATABASE SAMPLE_DB; USE SCHEMA SAMPLE_SCHEMA; -- 外部ステージの作成 CREATE OR REPLACE STAGE STG_SAMPLE STORAGE_INTEGRATION = S3_INT URL = '' # 自身のS3バケットパス ; -- テーブルにUDTFを使ってデータをロード CREATE OR REPLACE TABLE TBL_ADMIN_DISTRICT AS SELECT PROPERTIES, TO_GEOGRAPHY(WKB, TRUE) AS GEOGRAPHY FROM TABLE(LOAD_SHAPEFILE(BUILD_SCOPED_FILE_URL(@STAGE_MESH, 'N03-20230101_GML.zip'),'N03-23_230101.shp')) ;
ロードが完了した後、中身を確認してみると

うん、うまくロードできてそう。
ちなみにテーブルサイズは約532MB

試しに空間処理のクエリを投げて確かめてみる。
東京ドームのポイントデータ(緯度経度)がどこの行政区域に位置するかクエリを実行してみる。
SELECT * FROM TBL_ADMIN_DISTRICT T1 WHERE ST_INTERSECTS(ST_MAKEPOINT(139.751994, 35.705493), T1.GEOGRAPHY);
東京ドームは文京区に位置するのでロードしたデータは大丈夫そう。

まとめ
Snowflakeにshapefile形式のデータのロードできるか試してみた。
独自の関数を用意する必要があるが、癖のあるshapfileも読み込めるのはGISデータを扱う人にとってはありがたいのかなと思う。
Snowflakeは地理情報関数も豊富だし、Streamlitと組み合わせて可視化もできるのも嬉しい。
次は可視化を試してみたいな。だれかの参考になれればと思います。
【Snowflake】S3 Storage Integration作成時にはS3バケットポリシーにも注意する
概要
SnowflakeのS3 Storage Integrationで設定する対象のS3バケットにおいて、S3バケットポリシーにaws:PrincipalOrgIDを条件にしたPut系の権限を設定している場合は注意しよう。
比較的ニッチな話題ではあるが、なぜ注意が必要かというと以下のことが理由である。
- S3 Storage IntegrationでGet系の権限を設定したにも関わらず、SnowflakeからそのS3へUnload(Put)ができる(本来意図している挙動とは異なる)
aws:PrincipaOrgIDとは?
AWS IAMポリシーのConditionの条件キーの一つ。(参考)
この条件を使えば、AWS Organizationに属するIdentifierのみにアクションを制御することができる。
ケースとしてはS3バケットへのアクセスをAWS Organization内に限定する場合などが挙げられる。
{
"Version": "2012-10-17",
"Statement": {
"Sid": "AllowPutObject",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::policy-ninja-dev/*",
"Condition": {"StringEquals":
{"aws:PrincipalOrgID":"o-xxxxxxxxxxx"}
}
}
}
指定したorganization以外からのS3バケットへのアクセスを拒否することができる。
問題になるケース
早速、問題となるケースを手順を示しながら見ていく。
1. [AWS] S3バケットにバケットポリシーを設定
事前に作成したS3バケットにList系、Get系、Put系のアクションを許可するポリシーを設定する。
指定したPrincipalOrgIDであれば、誰でも許可されたアクションを実行できる。

2. [AWS] S3 Storage Integration用のIAMポリシーの作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion"
],
"Resource": "arn:aws:s3:::XXXXXX/*" #自身のS3バケットパス
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::XXXXXX", #自身のS3バケットパス
"Condition": {
"StringLike": {
"s3:prefix": [
"*"
]
}
}
}
]
}
このポリシーをアタッチしたIAMロールを作成する。
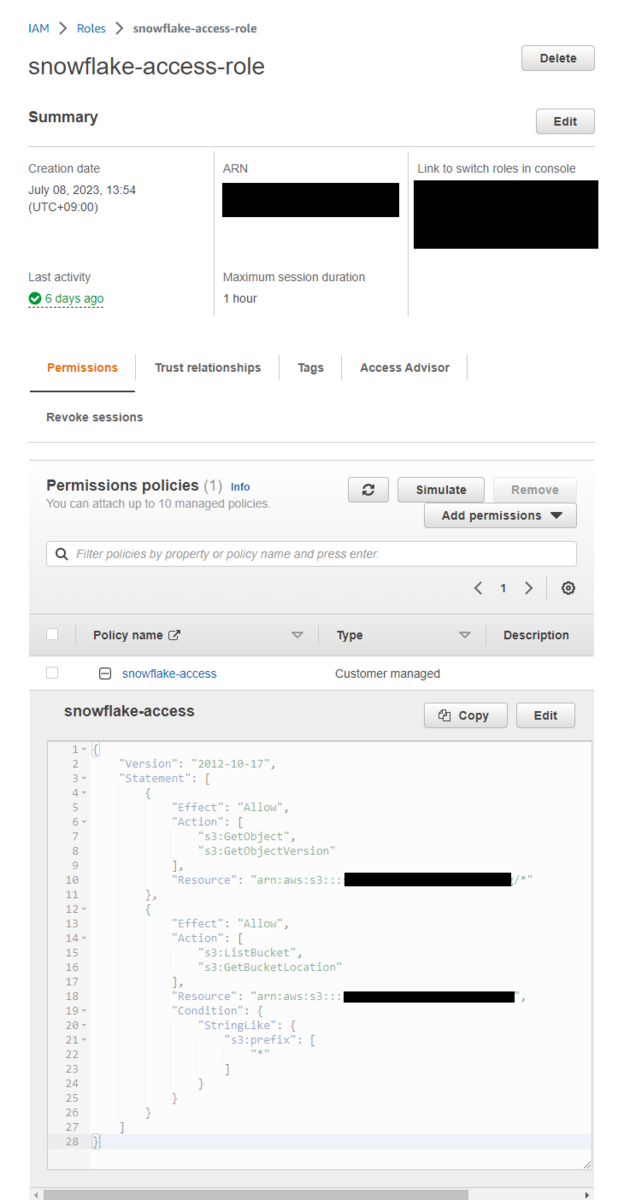
3. [Snowflake] S3 Storage Integrationを作成
CREATE OR REPLACE STORAGE INTEGRATION S3_INT
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::XXXXXXXX' #自身のIAMロールのARN
STORAGE_ALLOWED_LOCATIONS = ('s3://XXXXXXX/') #自身のS3バケットパス
;
以下のSQLを実行し、返却された結果のSTORAGE_AWS_IAM_USER_ARNとSTORAGE_AWS_EXTERNAL_IDをメモしておく。
DESC INTEGRATION S3_INT;
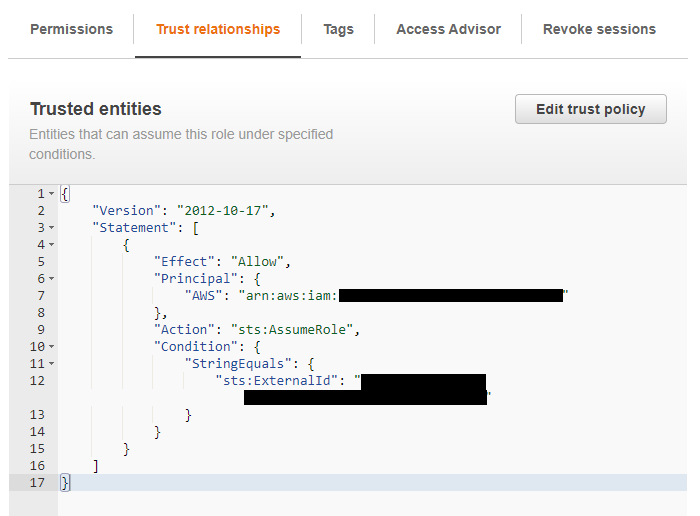
4. [AWS] IAMロールの信頼関係の設定
先程メモしたプロパティをIAMロールの信頼関係において以下のように設定する。
PrincipalのAWS →
STORAGE_AWS_IAM_USER_ARNExternalId →
STORAGE_AWS_EXTERNAL_ID
5. [Snowflake] S3バケット内のフォルダにUnloadしてみる
今回作成したIntegrationはGetやList系のみのアクションのみが可能なため、本来であればSnowflakeからS3に対してPutはできないはず。
サンプルテーブルを用意し、そのテーブルをS3バケットに対してUnloadをすると、、
USE DATABASE SAMPLE_DB; USE SCHEMA SAMPLE_SCHEMA; CREATE TABLE SAMPLE_TABLE (ID INT, NAME VARCHAR) AS SELECT 1 AS ID, 'USER1' AS NAME UNION ALL SELECT 2 AS ID, 'USER2' AS NAME ; COPY INTO 's3://XXXXXXX/' #自身のS3バケットパス FROM SAMPLE_TABLE STORAGE_INTEGRATION = S3_INT FILE_FORMAT = (TYPE = CSV) ;
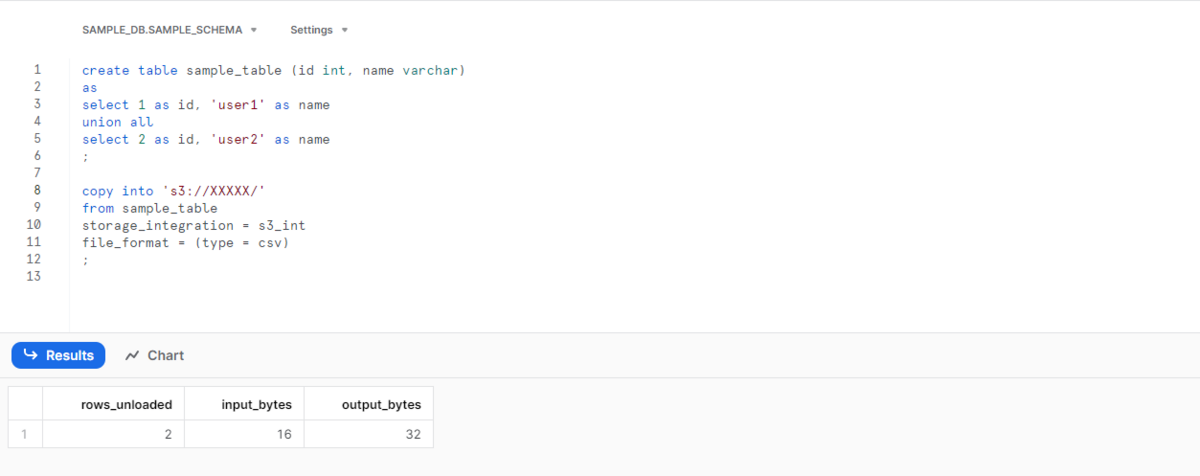
なんとPutができてしまう!
Snowflake側のIAMユーザーに対してAssumeRoleする際にPrincipalOrgIDの属性も持つようになるため、S3バケットに書き込みが可能となる。
Snowflake側ではこの挙動を制限できないので、S3バケットポリシーの許可範囲を絞る方法で解決できる。
まとめ
S3のバケットポリシーによってはSnowflakeのGetやList系のみ許可されたS3 Storage Integrationを用いたとしても、S3バケットへのPutが可能になるケースがあるので注意しましょう。
【Snowflake】権限の可視化・レポート作成ツールsfgrantreportを試してみた
概要
Snowflakeにおけるオブジェクトの権限管理はロールベースで行うため、ロールの数が多くなってくるとsnowsight上でRoleグラフが複雑になって見にくくなる。
全体をみたいときには少し不便だが、ロール階層を可視化やレポートを自動作成してくれる「sfgrantreport」なるツールがあったので試してみた。
sfgrantとは?
Snowflakeの「ロールやそれに紐づいている権限、ロール階層」をHTML形式や表形式(.xlsx)で出力してくれるツール
定期的な監視や監査など、開発よりも運用面で役に立つものかなと思う
使い方
1. 事前準備
- snowsqlのインストール
- graphvizのインストール
2. sfgrantのインストール
各OSに応じたzipファイルをダウンロードする
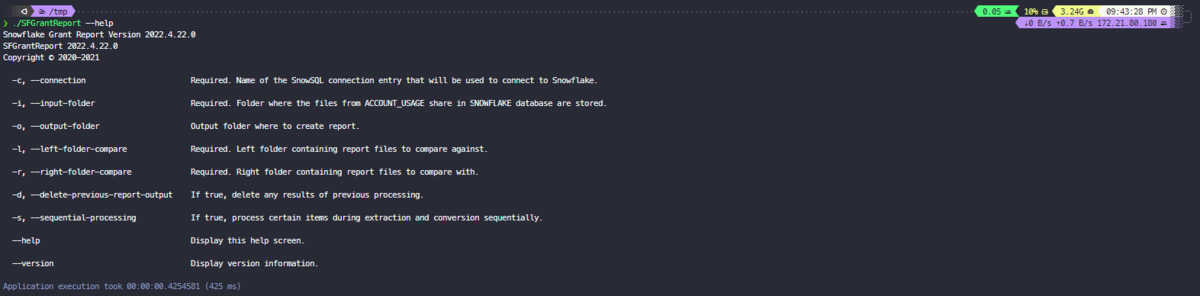
自分の環境がUbuntuなのでLinux版をダウンロードする
$ cd /tmp $ curl -o https://github.com/Snowflake-Labs/sfgrantreport/releases/latest $ ./SFGrantReport --help
正常に実行できればコマンドオプションが表示される
3. グラフレポートを作成
-oオプションで出力先のフォルダを指定できる
$ mkdir -p ~/myreport $ /tmp/SFGrantReport -c mysnowflakeconnection -o ~/myreport
少々時間がかかるが、完了すると出力先フォルダにレポートが出力される。
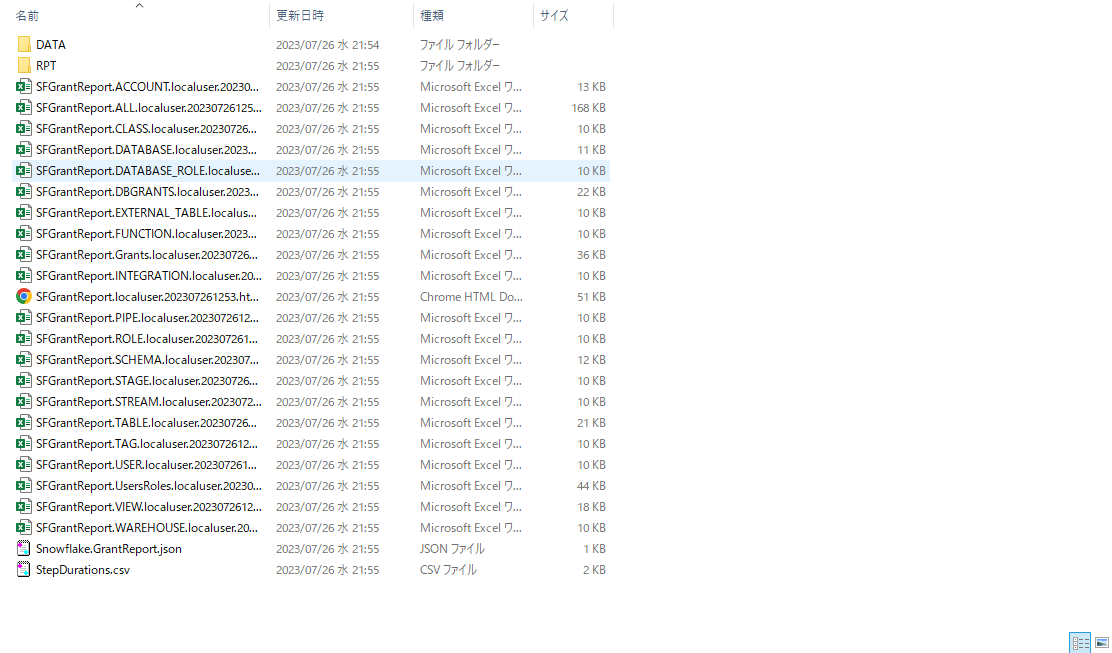
かなりの数のファイルが出力されるが、HTMLファイルとSFGrantReport.ALLという名前の.xslxファイルを見とけばひとまず問題ない。
4. レポートの中身
HTMLのレポート
ロールごとにどのオブジェクトに権限が紐づいているかを一目でわかる。
特にどのロールにも紐づいてないロールがわかるので、権限設定漏れやベストプラクティスやルールに沿っていないロールが直感的にわかる。
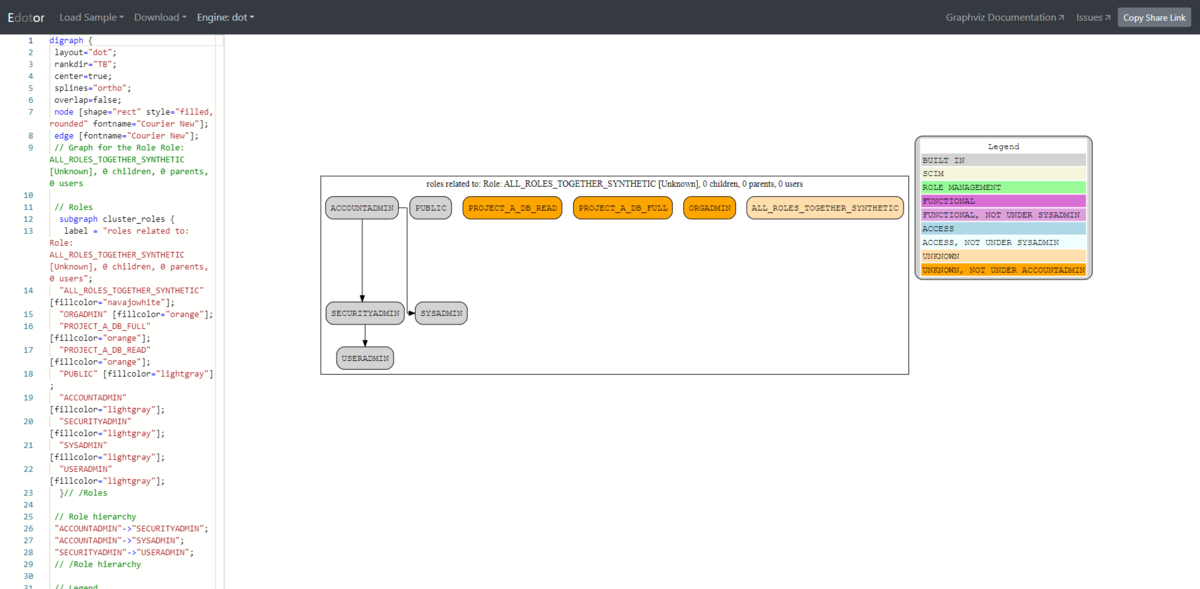
ACCOUNTADMINロールのページを選択するとACCOUNTADMINロールにフォーカスしたロール権限を見ることができる。
さらに凡例では
- システムロール
- Functional Role
- Access Role
- SYSADMINにGRANTされてないロール
- どのロールにもGRANTされてない独立したロール
ロールごとに色付けされているのも見やすくていい。
注意点としては、Snowflakeのリソースが多い場合は、ロールや権限を可視化してもやはり見にくくなるのは避けられない。
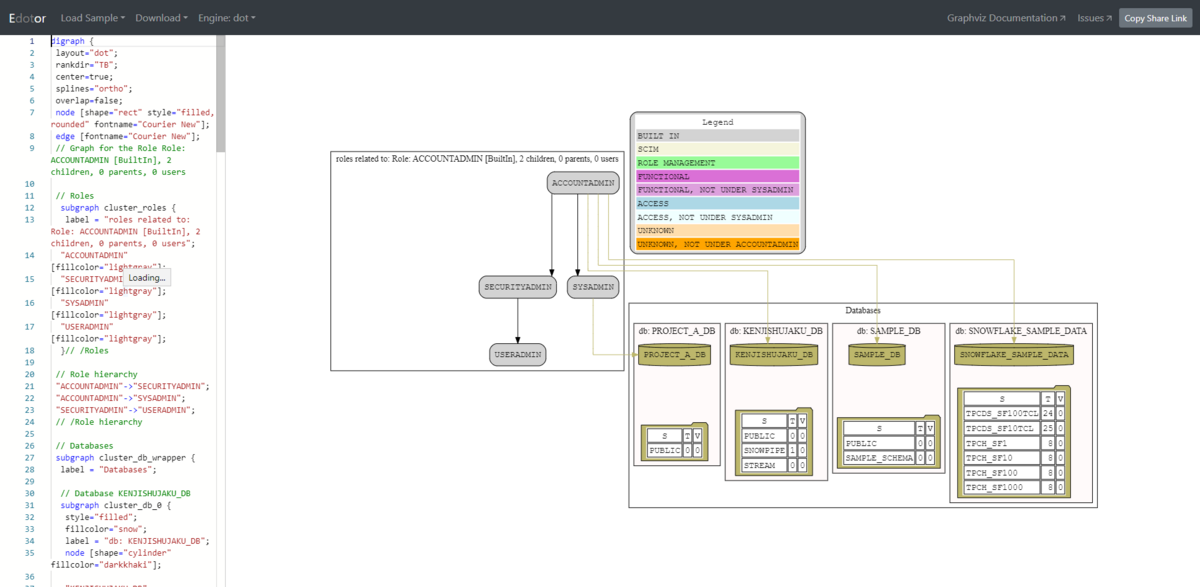
EXECELのレポート
UserやRole, Grantなど各オブジェクトごとにシートが分かれている。
少し見づらさはあるが、ユースケースとしては
- 退職したユーザーが削除されているか
- ACCOUTADMINなど権限の強いロールに特定のユーザーのみGRANTされているかの確認
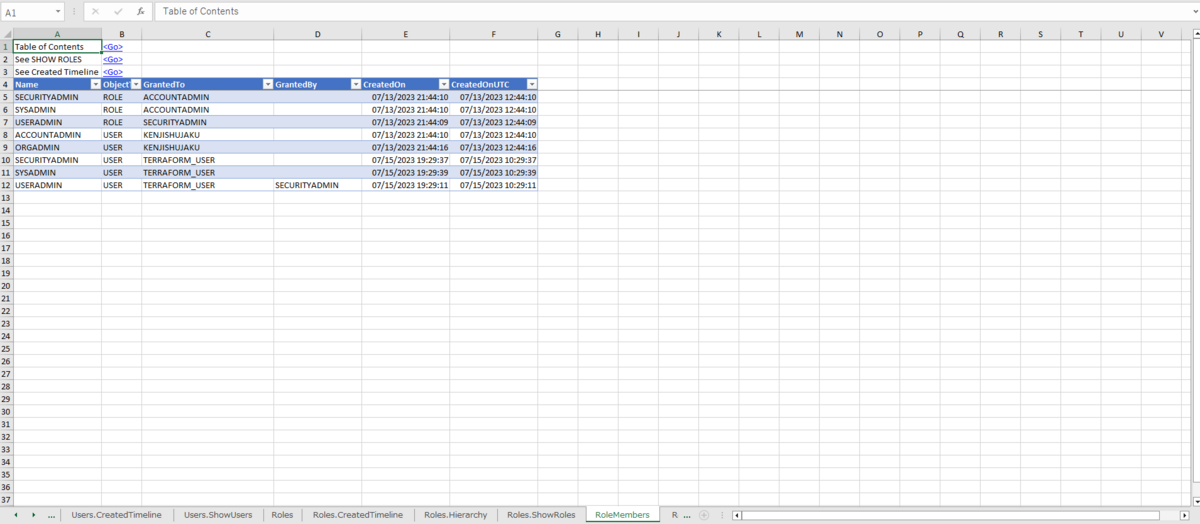
特定の項目だけをみたい場合は、他の出力されたファイルをみるのがおすすめ。
まとめ
sfgrantreportを試してみたが、思ってたより多くの情報をレポートにまとめてくれるのはありがたい。
snowsqlとgraphvizを利用してSnowflakeのロールに関するレポートを出力してくれるので、定期的なジョブを作成することで、セキュリティや監査目的で利用するのもありかな。
【Snowflake】S3のバケット通知から外部テーブルの自動更新を設定する
概要
S3バケットからのイベントトリガーで外部テーブルを自動更新する方法を試してみる。
データをSnowflakeにロードしてくる方法はSnowpipeやCOPYコマンドなどあるが、外部テーブルを利用するメリットは、Vectorized Scannerが使える点がある(データ形式がParquetのみ)。
なお利用するリソースは以下のとおり
- S3とイベント通知
- External Stage
- External Table
Vectorized Scannerとは?
スキャンするデータ形式がParquetの場合、通常のScanより高速なScanを可能にするScanner。ロードするデータサイズが大きい場合、高速にロードができる。
※ドキュメントに明記されてないが、Vectorized Scannerはデフォルトで無効になっているので有効にしたい場合はサポートに問い合わせて有効にしてもらう。
参考になった記事
- External Tables Are Now Generally Available on Snowflake
- How to Batch Ingest Parquet Fast with Snowflake
- External Table で Vectorized Scanner を使いつつ SELECT * したいときに EXCLUDE 句が便利
データ準備
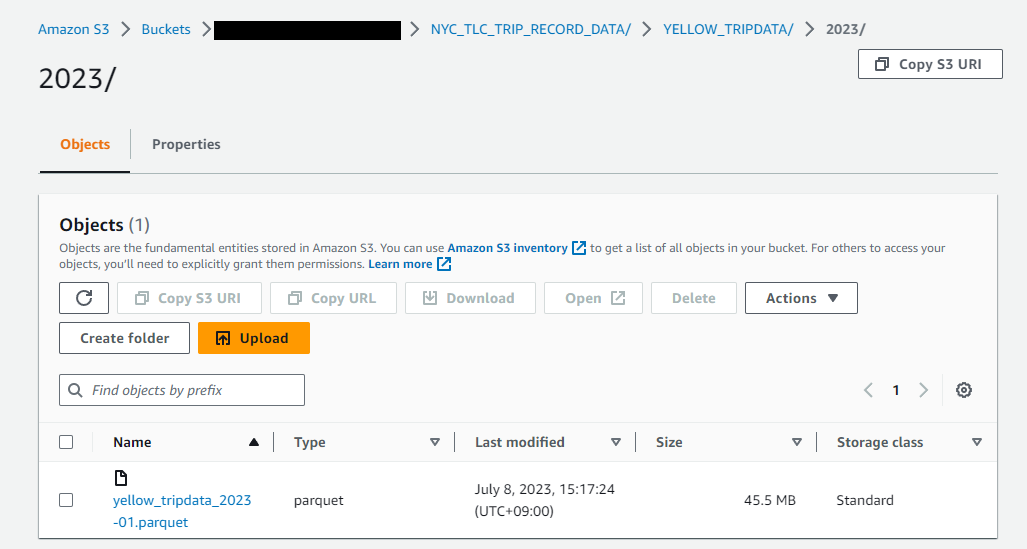
オープンデータであるNYCのYellowTaxITripRecordsを利用する。
2023年の1月のParquetファイル(yellow_tripdata_2023-01.parquet)をS3バケットに予めアップロードしておく。
リソース作成
以下の手順は割愛する
- S3バケット作成
- S3へのSTORAGE INTEGRATION作成
1. 外部ステージの作成
S3のバケットURLを指定して外部ステージを作成する。STORAGE INTEGRATIONは自身のものを使用する。
CREATE STAGE ext_stg_nyc_taxi_yellow_trip STORAGE_INTEGRATION = s3_int # 自身のS3 STORAGE INTEGRATION URL = '' # 自身のS3パス FILE_FORMAT = (type=parquet) ;
2. 外部テーブルの作成
先程の作成した外部ステージをLOCATIONに指定し、外部テーブルを作成する。
ここではファイル名のYYYYMM部分を抽出した値をパーティション用のカラムとして追加している。
CREATE EXTERNAL TABLE ext_tbl_nyc_taxi_yellow_trip (
yyyymm string(6) as (substr(split_part(metadata$filename,'_', 8), 1, 4) || substr(split_part(metadata$filename,'_', 8), 6, 2))
)
PARTITION BY (yyyymm)
LOCATION=@ext_stg_nyc_taxi_yellow_trip
FILE_FORMAT=(type=parquet)
;
3. 外部テーブルのSnowflake用のSQS ARNの確認
外部テーブル作成時に自動で設定されるSnowflakeが管理するSQSのARNをコピーする。
SHOW EXTERNAL TABLES;

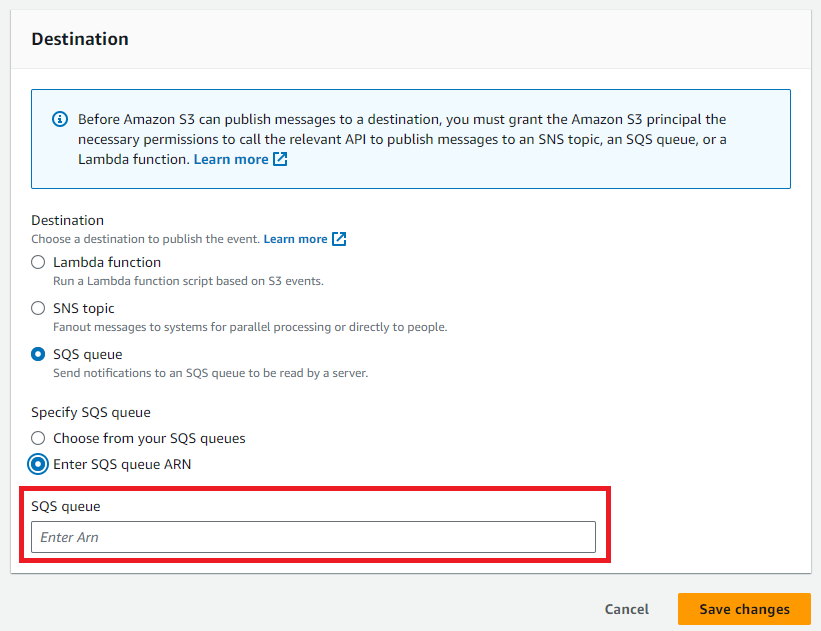
4. S3イベント通知の作成
S3イベント通知作成する際に、3で確認したSQSのArnを指定する。
S3バケットが更新されるとこのSQSを利用して外部テーブルの自動更新がされる。
※既にS3イベント通知先が存在している場合はSNSの利用を検討する(参考)
5. 外部テーブルの手動更新
ALTER EXTERNAL TABLE ext_tbl_nyc_taxi_yellow_trip REFRESH;
この状態だと事前準備した202301のデータがあるはずなので確かめてみると
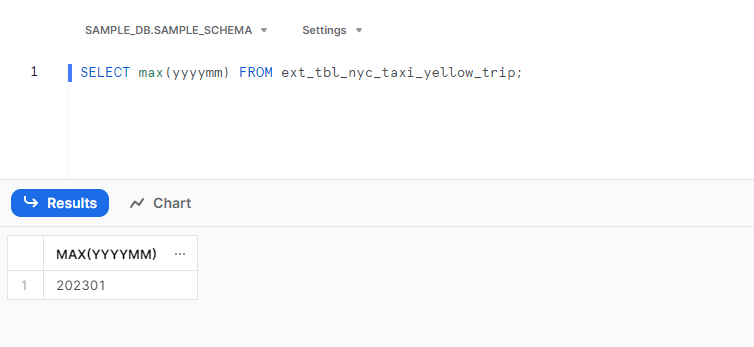
確かにデータとしてはありそう。
6. 外部テーブルが自動更新されているか確認
次に、S3に202302のファイルを試しにアップロードして少し待ってみると。。。
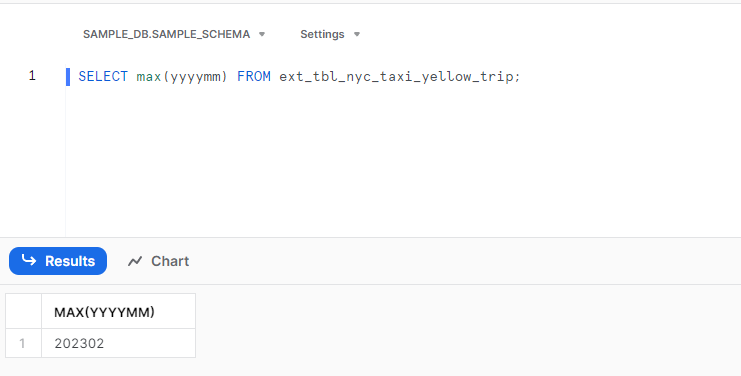
ちゃんと外部テーブルのS3メタデータが自動で更新されている!
まとめ
今回はS3バケットのイベント通知を利用した外部テーブルの更新する方法を試した。
思ってたより設定が簡単。
外部テーブルに対してStreamを作成することでCDCを利用した内部テーブルへのロードも可能になるので今度試してみる。
【Snowflake】LambdaからSnowflakeへクエリを投げる
背景
SnowflakeへのクエリはSnowsight上やSnowSQLでしか試したことがなかったので、Pythonコネクタを利用してLambdaからSnowflakeへクエリを投げる方法を試してみる。
内容
今回はLambdaとLambda Layerで構成し、SAMでデプロイをしてみる。
準備するもの
./connect_snowflake ├── layer -- lambda layer用のディレクトリ ├── lambda_function.py -- ソースコード ├── samconfig.toml -- SAM用のconfigファイル └── template.yaml -- SAM用のテンプレートファイル
各ファイルの中身は以下のようになっている。 LambdaからSnowflakeクエリを非同期で投げ、そのクエリIDを返却するものになっている。
lambda_function.py
import json
import time
import snowflake.connector
from snowflake.connector import ProgrammingError
def lambda_handler(event, context):
user='' # 自身のユーザ名
password='' # 自身のパスワード
account='' # 自身のSnowflakeアカウント
ctx = snowflake.connector.connect(
user=user,
password=password,
account=account
)
cs = ctx.cursor()
try:
# クエリを非同期で投げる
cs.execute_async("SELECT current_version();")
query_id = cs.sfqid
# クエリが実行完了するまで待機する
while ctx.is_still_running(ctx.get_query_status_throw_if_error(query_id)):
time.sleep(1)
except ProgrammingError as err:
print('Programming Error: {0}'.format(err))
raise err
finally:
cs.close()
ctx.close()
return {
'statusCode': 200,
'body': json.dumps(query_id)
}
template.yml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Connect to Snowflake
Resources:
ConnectSnowflakeFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: ./
Handler: lambda_function.lambda_handler
Runtime: python3.10
PackageType: Zip
Architectures:
- x86_64
Layers:
- !Ref Layer
Timeout: 10
Layer:
Type: AWS::Serverless::LayerVersion
Properties:
ContentUri: layer/
CompatibleRuntimes:
- python3.10
Outputs:
LambdaFunction:
Description: "Connect Snowflake Lambda Function ARN"
Value: !GetAtt ConnectSnowflakeFunction.Arn
LmabdaFunctionIamRole:
Description: "Implicit IAM Role created for Connect Snowflake Function"
Value: !GetAtt ConnectSnowflakeFunctionRole.Arn
samconfig.toml
version = 0.1 [default] [default.deploy] [default.deploy.parameters] stack_name = "connect-snowflake" s3_bucket = "" # 自身のS3バケット名 s3_prefix = "connect-snowflake" region = "ap-northeast-1" capabilities = "CAPABILITY_IAM"
SAMでデプロイ
まず、Lambda Layerの作成を行う。
layerディレクトリ内にsnowflake-connector-pythonのパッケージをインストールする。
$ cd ./layer $ docker run --rm -v $(pwd):/var/task public.ecr.aws/sam/build-python3.10:latest pip install "snowflake-connector-python" -t python/lib/python3.10/site-packages/
コマンドを実行するとlayerディレクトリ配下にsnowflake-connector-pythonのパッケージがインストールされる。
※注意したいのは、ビルド環境とLambdaの実行環境のアーキテクチャ(x86_64 or arm64)を合わせるようにすること。Macで開発している場合、パッケージはarmベースのものがインストールされるため、このライブラリをx86_64のLambdaで実行するとエラーが発生するので気を付けたい。
このエラーに関して自分が参考になった記事を貼っておく。
- How do I add Python packages with compiled binaries to my deployment package and make the package compatible with Lambda?
- 【Serverless Framework】コンテナイメージを使ってPackageする際はアーキテクチャに気を付ける【Python】
- Add FAQ entry how to download and provide AWS Lambda bundle #6391
以下のコマンドでデプロイしていく。
$ cd ../ $ sam build $ sam deploy --guided
デプロイ完了。SAMなので簡単!

Lambda上でテストが成功すると実行したクエリIDが表示される。
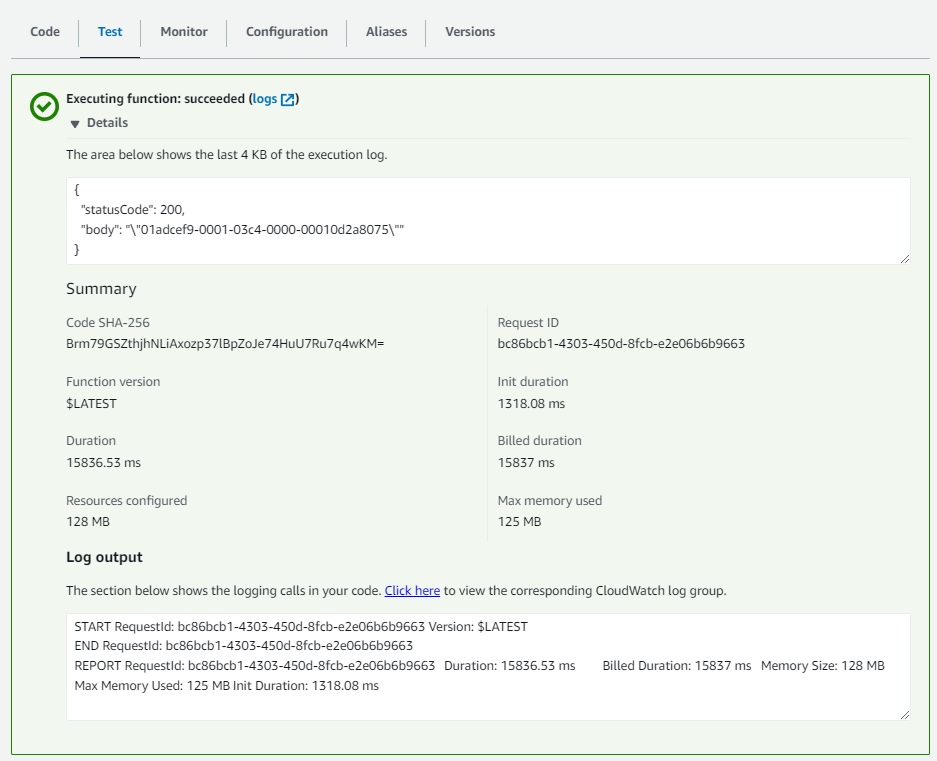
まとめ
【Snowflake】ロール設計の際にはグローバル権限も考慮しよう
背景
業務でSnowflakeのロール設計をしたのだが、後になってグルーバル権限についても考慮する必要がでてきたので、その時に学んだことを記す。
グローバル権限とは?
アカウント全体に適用される権限であり、通常はACCOUNTADMINのみによって他のロールに付与することができる権限のこと。
グローバル権限一覧を見ると、CREATE WAREHOUSEやMANAGE GRANTSなどSnowflakeで重要な権限が含まれており、慎重な権限設定が必要になる。
以下の図でいうところのACCOUNTレイヤーが該当する。
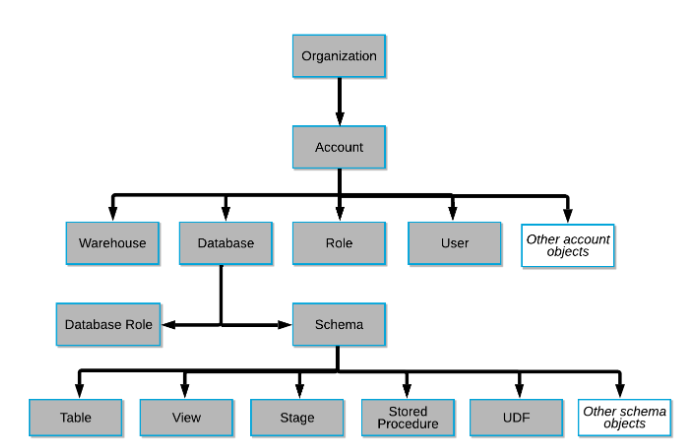
ロール設計時に注意すること
Snowflakeのオブジェクトへのアクセス制御モデルとしてRBACやDACが採用されているため、基本的に一般ユーザーがグローバル権限が必要となるケースは少ない。
自分もそう思っていたので、あまりグローバル権限に対して考慮ができておらず整理にするのに苦労した。
グローバル権限の何に注意すべきかというと以下の点になる。
1. EXECUTE TASKやEXECUTE ALERTなどは一般ユーザーでも必要
一般ユーザーがタスクやアラートを作成するケースにおいてはこれらの実行権限がないとそもそも実行できない。
2. グローバル権限のほとんどはACCOUNTADMINのみが付与できること
特にSnowflake基盤をIaCで管理している、かつACCOUNTADMINロール以外のロールで管理している場合には注意したい。
IaCで管理している場合はIaC用のロールであったり、ACCOUNTADMIN以外のシステムロールで管理することが多いと思うが、グローバル権限を付与する際にいちいちACCOUNTADMINロールを持つユーザーが設定しなくてはならない。
こうなるとIaCで管理するものとそうではないものの境界が曖昧になってしまう。
整理できていない場合は、グローバル権限を誰が管理するのか(誰が権限を付与できるようにするかか含め)、さらにIaCでも管理するのかを明確にするといいかもしれない。
まとめ
グローバル権限は一般ユーザーにも必要なケースがあったり、ACCOUNTADMINのみが付与可能だったりして、他の権限よりも特殊であるので扱いには少し考慮が必要。
グローバル権限の管理やユースケースの整理しておくと、ロール設計もよりよいものができるのではないかと思う。
Snowflakeのロール設計する人や基盤管理者の誰かの参考になればうれしいな。
番外編
ACCOUNTADMINのみが付与可能なロールはグローバル権限以外にもあるみたい。
Snowflakeサポートケースに関する権限(ex. MANAGE USER SUPPORT CASES)もACCOUNTADMINやORGADMINのみ付与可能。(サポートシステムへのアクセス)
【Snowflake】terraform-provider-snowflakeのenable_multiple_grantsにはまった話
背景
TerraformでSnowflake基盤を管理する際に、権限系のリソースオプションであるenable_multiple_grantsにはまったときの話。
TL;DR
こだわりなければ、権限に関するリソースオプションのenable_multiple_grants=trueにしておいていいかもしれない。
terraform-provider-snowflakeの0.68以上のバージョンを利用していればsnowflake_grant_privileges_to_roleリソースを利用する方がよさそう。
そもそもenable_multiple_grantsオプションとは?
(Boolean) When this is set to true, multiple grants of the same type can be created.
This will cause Terraform to not revoke grants applied to roles and objects outside Terraform.
公式のドキュメントをみると、どうやらTerraformで管理しているオブジェクトの権限に関して、Terraform外で設定された権限が存在する場合、剥奪するかどうかを決めることができるらしい。
true→ Terraform外で権限が設定されたとしてもなにもしないfalse→ Terraform外で設定した権限を剥奪するようになる
挙動については理解できたが、どうやら期待した動作と異なるケースがかなり見受けられる。
GithubのIssuesを見ても、権限に関するバグに遭遇している人は多そう。
内容
enable_mltiple_grantsに関するバグは多そうなので、今回は自分が遭遇したバグを紹介しようと思う。
例えば以下のような構成で考える。
- PROJECT_A_DBというDBが1つ
- DBのフルアクセス権限(ALL PRIVILEGES)を持つアクセスロール
- DBのRead-Only権限(READ)を持つアクセスロール

Terraformにおけるリソース定義は以下。
-- database
resource "snowflake_database" "project_a_db" {
provider = snowflake.sys_admin
name = upper("project_a_db")
}
-- access role for full access to a database
resource "snowflake_role" "project_a_db_full_access" {
provider = snowflake.user_admin
name = upper("project_a_db_full_access")
}
-- access role for read-only access to a database
resource "snowflake_role" "project_a_db_read_access" {
provider = snowflake.user_admin
name = upper("project_a_db_read_access")
}
-- grant full access role to a database
resource "snowflake_database_grant" "project_a_db_full_grants" {
provider = snowflake.sys_admin
database_name = snowflake_database.project_a_db.name
privilege = "ALL PRIVILEGES"
roles = [
snowflake_role.project_a_db_full_access.name
]
enable_multiple_grants = false
}
-- grant read-only access role to a database
resource "snowflake_database_grant" "project_a_db_read_grants" {
provider = snowflake.sys_admin
database_name = snowflake_database.project_a_db.name
privilege = "USAGE"
roles = [
snowflake_role.project_a_db_read_access.name
]
enable_multiple_grants = false
}
1回目のデプロイ
Snowflake上にPROJECT_DB_ABのDB権限に関しては、リソース定義通りに各ロールに対して権限が設定されていることがわかる。

2回目のデプロイ
問題はここ。
なにもリソースを更新していなくても、terraform planするとなぜか権限に関する差分がでてきてしまう。

さらに、terraform applyすると、PROJECT_A_DB_FULLに付与されていたUSAGE権限が剥奪されてしまう。

なぜ差分がでてくる?
はっきりとした原因はわかってないが、
DBのUSAGE権限が複数のロール(
PROJECT_A_DB_FULL,PROJECT_A_DB_READ)に付与されているその複数のロールが別々のリソースとして定義されている
を満たす場合、今回のようなバグに遭遇してしまう。
まとめ
結局のところenable_multiple_grants=trueにしておけば、今回の問題は解決されるみたいだけど、なんかモヤモヤ感がとれない。
enable_multiple_grantsに関してはバグが多く、はまることも多いが誰かの参考になればうれしいな。