【Snowflake】S3のバケット通知から外部テーブルの自動更新を設定する
概要
S3バケットからのイベントトリガーで外部テーブルを自動更新する方法を試してみる。
データをSnowflakeにロードしてくる方法はSnowpipeやCOPYコマンドなどあるが、外部テーブルを利用するメリットは、Vectorized Scannerが使える点がある(データ形式がParquetのみ)。
なお利用するリソースは以下のとおり
- S3とイベント通知
- External Stage
- External Table
Vectorized Scannerとは?
スキャンするデータ形式がParquetの場合、通常のScanより高速なScanを可能にするScanner。ロードするデータサイズが大きい場合、高速にロードができる。
※ドキュメントに明記されてないが、Vectorized Scannerはデフォルトで無効になっているので有効にしたい場合はサポートに問い合わせて有効にしてもらう。
参考になった記事
- External Tables Are Now Generally Available on Snowflake
- How to Batch Ingest Parquet Fast with Snowflake
- External Table で Vectorized Scanner を使いつつ SELECT * したいときに EXCLUDE 句が便利
データ準備
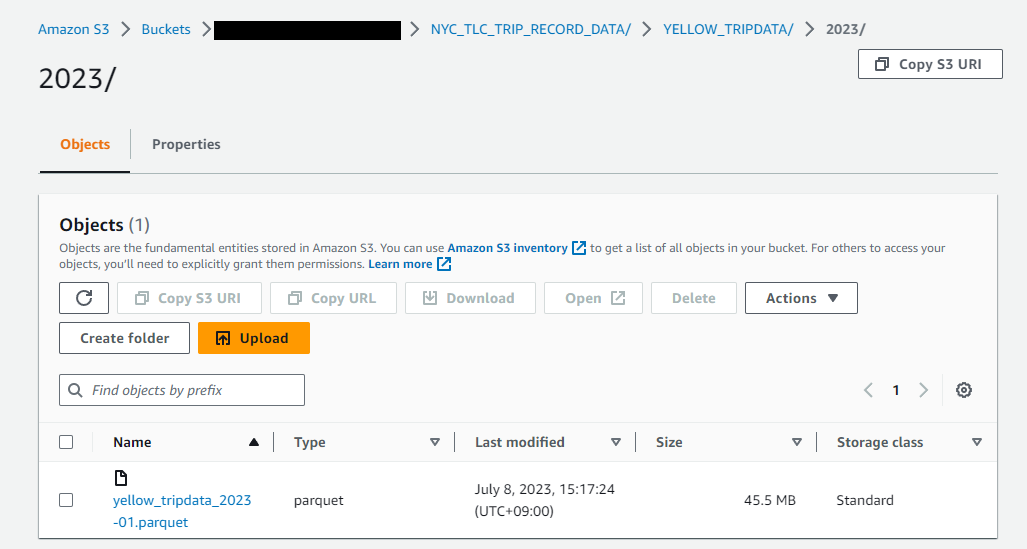
オープンデータであるNYCのYellowTaxITripRecordsを利用する。
2023年の1月のParquetファイル(yellow_tripdata_2023-01.parquet)をS3バケットに予めアップロードしておく。
リソース作成
以下の手順は割愛する
- S3バケット作成
- S3へのSTORAGE INTEGRATION作成
1. 外部ステージの作成
S3のバケットURLを指定して外部ステージを作成する。STORAGE INTEGRATIONは自身のものを使用する。
CREATE STAGE ext_stg_nyc_taxi_yellow_trip STORAGE_INTEGRATION = s3_int # 自身のS3 STORAGE INTEGRATION URL = '' # 自身のS3パス FILE_FORMAT = (type=parquet) ;
2. 外部テーブルの作成
先程の作成した外部ステージをLOCATIONに指定し、外部テーブルを作成する。
ここではファイル名のYYYYMM部分を抽出した値をパーティション用のカラムとして追加している。
CREATE EXTERNAL TABLE ext_tbl_nyc_taxi_yellow_trip (
yyyymm string(6) as (substr(split_part(metadata$filename,'_', 8), 1, 4) || substr(split_part(metadata$filename,'_', 8), 6, 2))
)
PARTITION BY (yyyymm)
LOCATION=@ext_stg_nyc_taxi_yellow_trip
FILE_FORMAT=(type=parquet)
;
3. 外部テーブルのSnowflake用のSQS ARNの確認
外部テーブル作成時に自動で設定されるSnowflakeが管理するSQSのARNをコピーする。
SHOW EXTERNAL TABLES;

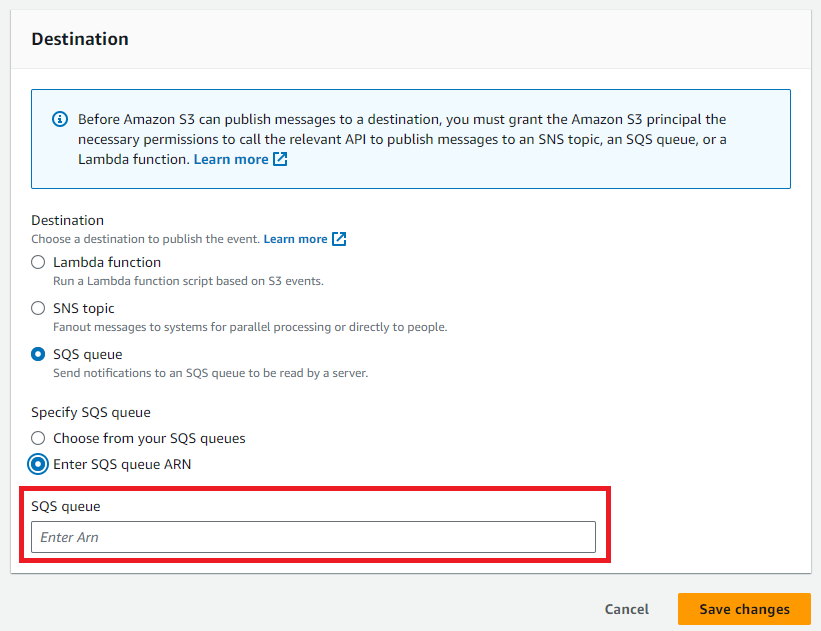
4. S3イベント通知の作成
S3イベント通知作成する際に、3で確認したSQSのArnを指定する。
S3バケットが更新されるとこのSQSを利用して外部テーブルの自動更新がされる。
※既にS3イベント通知先が存在している場合はSNSの利用を検討する(参考)
5. 外部テーブルの手動更新
ALTER EXTERNAL TABLE ext_tbl_nyc_taxi_yellow_trip REFRESH;
この状態だと事前準備した202301のデータがあるはずなので確かめてみると
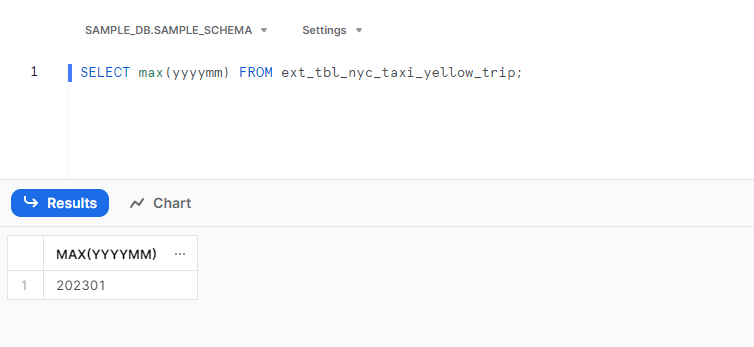
確かにデータとしてはありそう。
6. 外部テーブルが自動更新されているか確認
次に、S3に202302のファイルを試しにアップロードして少し待ってみると。。。
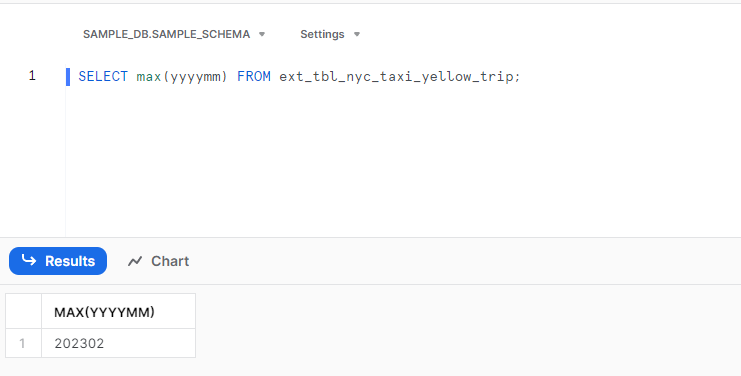
ちゃんと外部テーブルのS3メタデータが自動で更新されている!
まとめ
今回はS3バケットのイベント通知を利用した外部テーブルの更新する方法を試した。
思ってたより設定が簡単。
外部テーブルに対してStreamを作成することでCDCを利用した内部テーブルへのロードも可能になるので今度試してみる。